What AI Can and Cannot Do with Your Company Documents
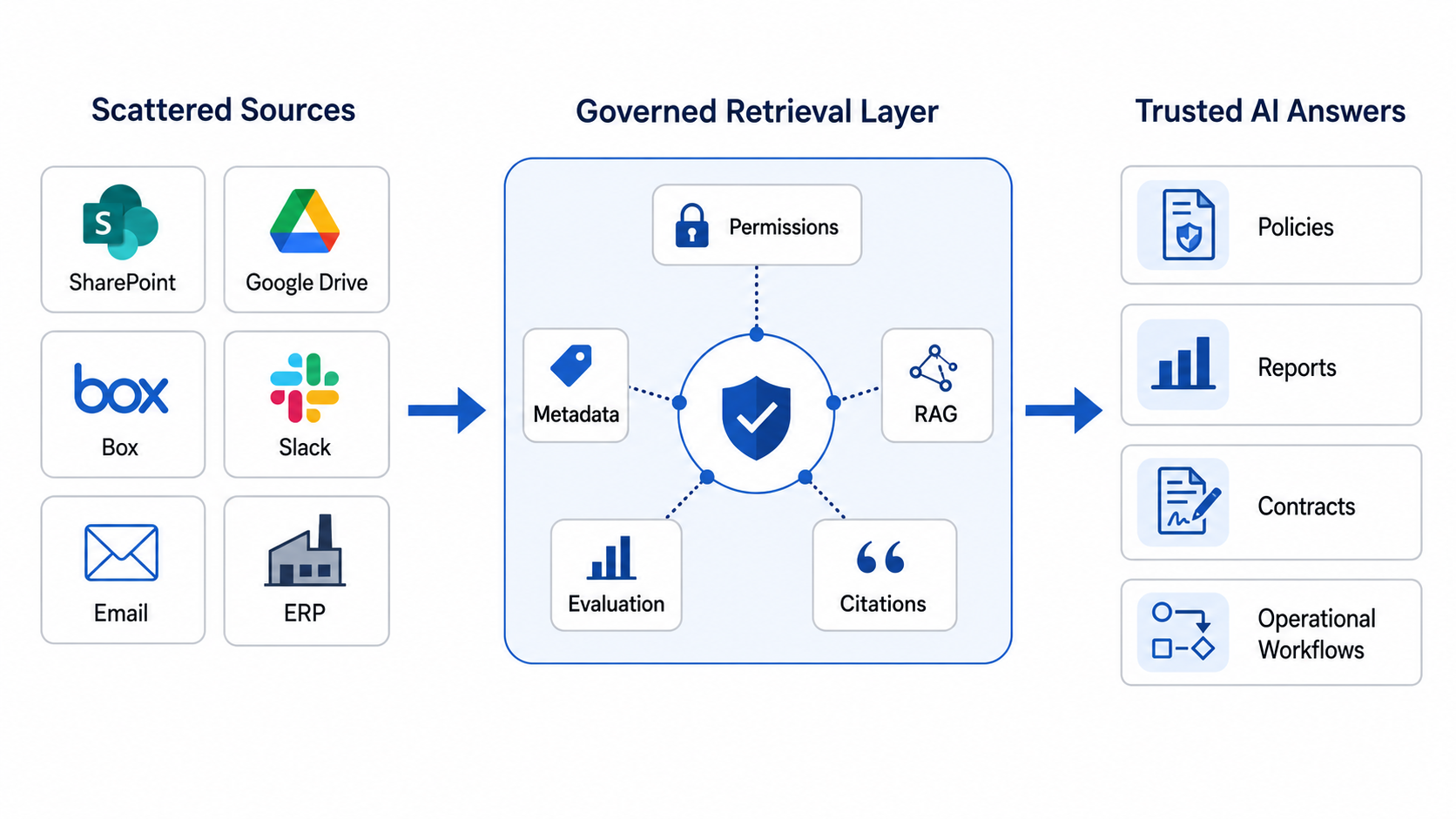
Most organizations already have the knowledge they need. The problem is that it is scattered across SharePoint folders, Google Drive, Box, Egnyte, Slack threads, email inboxes, ERP systems, PDFs, spreadsheets, and legacy repositories. Employees waste time searching, copying, reconciling, and asking colleagues for answers that technically already exist.
That is why enterprise AI is moving quickly toward agents and connectors. OpenAI now describes ChatGPT Enterprise as being able to use agents and connect to company data from tools such as Microsoft SharePoint, Google Drive, GitHub, Box, and more. OpenAI’s company knowledge materials also note that work context often lives across docs, files, messages, emails, tickets, and project trackers, and that connected tools can help ChatGPT bring that context together with citations.
But there is an important reality check: AI does not magically “know” everything in your company documents. It retrieves, ranks, summarizes, and reasons over the information it can access. The quality of the answer depends on the quality of the content, the search architecture, the permissions model, and the way the question is asked.
What AI Can Do: Search, Retrieve, Summarize, and Compare
At its best, AI can make enterprise knowledge dramatically easier to use. A well-designed AI document system can answer questions like:
“What is our current vendor termination policy?”
“Summarize the latest client feedback across email, Slack, and support tickets.”
“Compare these three contracts and flag unusual indemnity language.”
“Find all procedures related to month-end close and turn them into a checklist.”
Behind the scenes, this often uses retrieval-augmented generation, or RAG. RAG combines search with a large language model. Instead of asking the model to answer only from its general training, the system searches your approved knowledge sources, retrieves relevant passages, and uses those passages to draft a grounded answer. OpenAI’s file search documentation describes this as enabling models to retrieve information from previously uploaded files using semantic and keyword search before generating a response.
This is powerful because traditional keyword search often misses relevant material. For example, an employee may search for “customer cancellation policy,” while the actual document says “termination of services.” Semantic search can recognize that those ideas are related. OpenAI’s retrieval documentation explains that semantic search can surface similar results even when they match few or no exact keywords.
What AI Cannot Do: Fix Broken Knowledge Automatically
AI has limits. It cannot reliably answer from documents it cannot access. It cannot always resolve contradictions between outdated policies and newer guidance. It cannot infer missing approvals, rebuild broken folder permissions, or know which “final_final_v7” file is truly authoritative unless the system gives it that context.
Context windows also matter. A context window is the amount of information a model can consider at one time. Large files are often chunked into smaller sections, indexed, and retrieved as needed. That means the model may not be reading every word of every document for every question. If the most relevant chunk is not retrieved, the answer can be incomplete.
File limits matter too. In ChatGPT, OpenAI’s File Uploads FAQ lists restrictions such as a 512MB hard limit per uploaded file, a 2 million token cap for text and document files, spreadsheet limits, image limits, and user or organization storage caps. These limits are manageable, but they reinforce the need for thoughtful document selection, indexing, and governance rather than simply uploading everything and hoping for the best.
Then there are hallucinations. A hallucination is when an AI system produces an answer that sounds confident but is unsupported, incomplete, or wrong. RAG reduces this risk by grounding answers in retrieved sources, but it does not eliminate the risk. Poor document quality, stale information, vague prompts, missing metadata, and weak evaluation processes can still lead to bad outputs.
Why Document Structure Matters
Document structure is one of the most overlooked success factors in enterprise AI. AI performs better when documents have clear titles, dates, owners, section headings, version history, consistent terminology, and machine-readable text. A scanned PDF with no headings is harder to use than a well-structured policy page. A spreadsheet with clear column names is easier to interpret than one filled with merged cells, abbreviations, and hidden assumptions.
Structure also supports trust. If an AI answer cites the source, shows the date, identifies the document owner, and flags conflicting guidance, users can verify the response instead of accepting it blindly. This is especially important in regulated environments where compliance, auditability, and accountability matter.
For companies with scattered knowledge, the goal is not just “connect everything.” The goal is to design a governed knowledge layer: approved sources, clear access controls, retrieval logic, evaluation tests, and human review for high-risk decisions.
How EAIS Helps Companies Make Document AI Useful
EAIS approaches document AI as an operating model, not a plug-in. Its capabilities include Information Solutions using RAG and GenAI to create policy-aware answers for content workflows, compliance, and audit needs, along with Data & Integration work that connects systems, cleans and transforms data, and deploys APIs and pipelines for production-ready AI.
This aligns with EAIS’s broader Keystone Operating Model: start with quick wins, co-build transparently in the client environment, embed governance from day one, and drive adoption through training and practical handover. For document AI, that means identifying the highest-value workflows first, validating source quality, testing answer accuracy, and building controls before scaling across departments.
The Takeaway
AI can help your organization find, summarize, compare, and act on company documents faster than traditional search. It can reduce busywork, improve consistency, and give teams better access to institutional knowledge.
But AI cannot compensate for chaotic data, unclear ownership, weak permissions, or missing governance. The companies that get the most value from AI document systems will be the ones that treat retrieval, structure, security, and adoption as part of the same solution.
EAIS helps organizations turn scattered company knowledge into governed, measurable AI workflows that people can trust and actually use. Learn more about how EAIS can support your goals.